1. メモリプール
-
プール化技術:
プールはコンピュータ技術において頻繁に使用されるデザインパターンであり、その意味はプログラムで頻繁に利用するコアリソースを事前に確保しプール内に格納し、プログラム自身で管理することで、リソースの利用効率を高め、かつプログラムの占有リソース量を保証する点にあります。よく使われるプール技術にはメモリプール、スレッドプール、コネクションプールなどがあり、特にメモリプールとスレッドプールが最も多く利用されます。
-
メモリプール
メモリプール (Memory Pool) は動的メモリ割り当ておよび管理技術の一つです。通常、開発者は
new、delete、malloc、freeなどのAPIを用いてメモリの割り当てと解放を行います。その結果、プログラムの長時間実行時に、確保するメモリブロックのサイズが不定であるため、頻繁に使用すると大量のメモリフラグメントが発生し、プログラムやOSのパフォーマンスが低下します。メモリプールは実際にメモリを使用する前に、大きなメモリブロック(メモリプール)を事前に確保しておき、メモリ要求があった場合にプールから動的に割り当て、解放時にはそのメモリをプールに戻し、可能であれば周囲の空きメモリブロックと結合します。メモリプールが不足した場合は自動的に拡大し、OSからさらに大きなメモリプールを要求します。
1.2 メモリプールが主に解決する問題
-
メモリフラグメント問題
メモリフラグメント問題とは、システム中に不連続で効率的に利用できないメモリ領域が多数存在する状態を指します。これらの不連続なメモリブロックは合計すれば要求を満たす容量があるものの、多数の小さな断片に分割されているため、大きな連続メモリを必要とする要求に対応できず、メモリ利用効率やシステム性能が低下します。
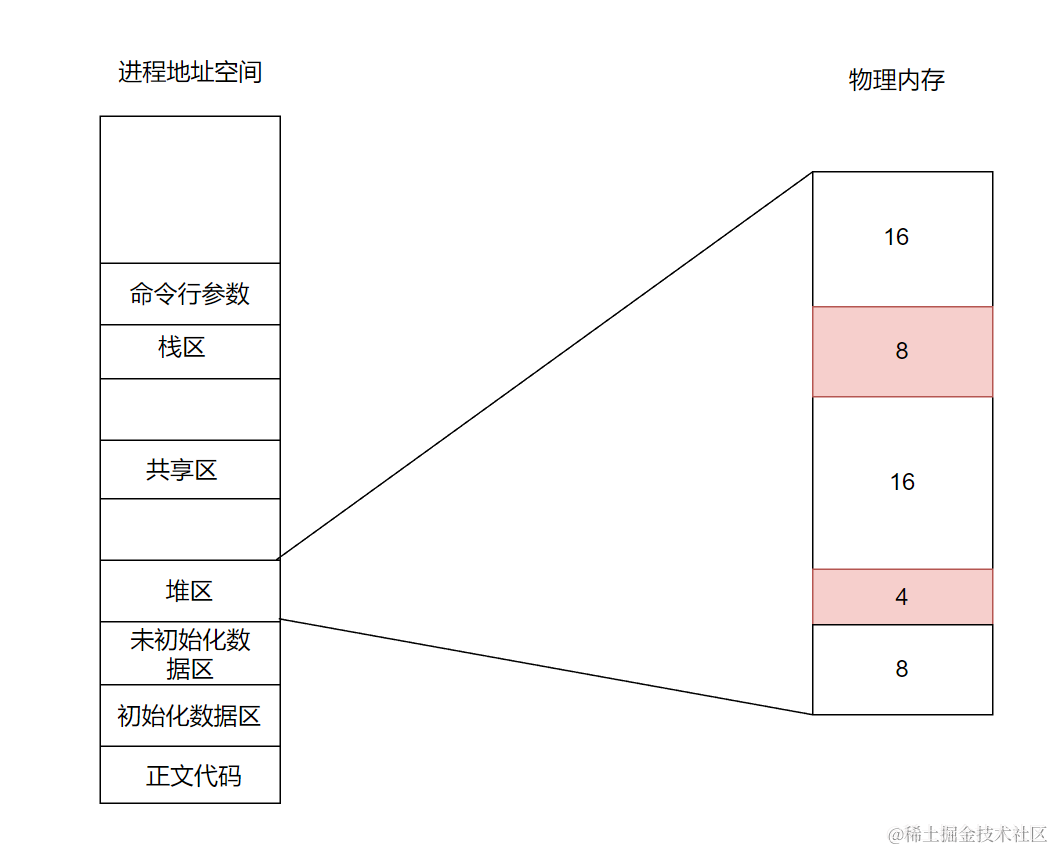
例として、システムが順に16byte、8byte、16byte、4byteを割り当て、さらに8byteが未割り当ての状態とします。ここで24byteの領域を割り当てようとすると、上の二つの16byteが解放され、合計空き容量は40byteですが、連続した24byteの領域を確保できません。これがメモリフラグメント問題です。
メモリフラグメントは主に二種類に分類されます:
- 内部フラグメント:プロセスやアプリケーションに割り当てられたメモリブロックのうち、実際に使用されていない部分を指します。例えば、大きなメモリ領域を要求したが実際にはその一部しか使用しなかった場合、残りの部分が内部フラグメントになります。
- 外部フラグメント:未割り当てのメモリブロック間に存在する小さな空きメモリの断片を指します。これらの空きメモリは合計では十分な容量があるものの、分散しているため効率的に利用できず、メモリ浪費につながります。上記の例は外部フラグメントの問題です。
メモリフラグメントの影響:
- メモリ利用率の低下: 一部のメモリが有効活用できず、システム全体のメモリ利用率が低下します。
- パフォーマンスへの影響: 大量のメモリフラグメントが存在すると、大きなメモリ要求に応えられず、頻繁なメモリ割り当て・解放が発生し、システムパフォーマンスに悪影響を与えます。
- メモリ管理オーバーヘッドの増加: メモリフラグメントにより管理アルゴリズムが複雑化し、オーバーヘッドが増大します。
メモリプールを使用することでメモリフラグメント問題を軽減できます。
- 割り当て効率の問題
事前に一定数のメモリブロックを割り当てておき、要求時にそれらから取得することで、メモリ割り当ての効率を向上させ、オーバーヘッドを削減できます。
メモリプールを導入すると、動的メモリ割り当ての際にプールから事前確保されたブロックを直接取得するため、OSへの頻繁なメモリ要求が不要になり、効率が向上します。
1.3 固定長メモリプールの実装
固定長メモリプール(オブジェクトプール)は、固定サイズのメモリブロックの割り当てと解放のみをサポートするメモリプールです。固定サイズのみ扱うため、パフォーマンスを極限まで高めることができ、メモリフラグメントなどの問題を考慮する必要がありません。
固定長メモリプールはテンプレートパラメータを用いて「固定長」を実現します。例えば、オブジェクト型として int を指定すれば、そのプールは4バイトのメモリのみを扱います。
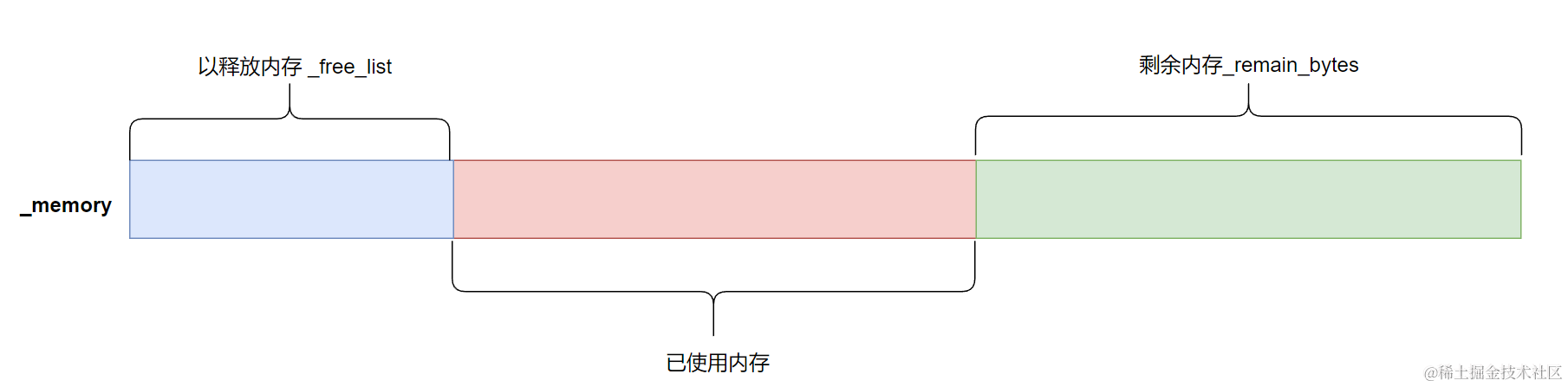
固定長メモリプールに必要なメンバ変数
事前に大きなメモリ領域をOSから確保し、管理する必要があります。残りバイト数、解放されたメモリを再利用するための自由リスト(フリーリスト)も必要です。
図解:
クラス図:
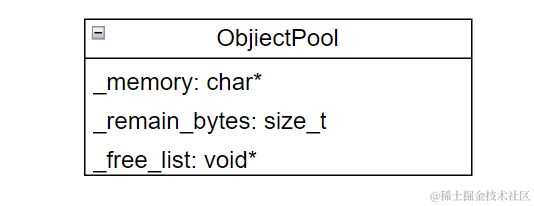
_memory: 確保した大きなメモリプールの先頭ポインタ_remain_bytes: メモリプール内の残りバイト数_free_list: 解放されたメモリブロックの自由リストの先頭ポインタ
メモリプールのポインタは char* 型にします。これにより、割り当てサイズ分だけ単純に加算するだけで次のアドレスが得られます。ポインタ加算は型のサイズに依存するため、int* + 8 は32バイト進みますが、char* + 8 は8バイト進むからです。
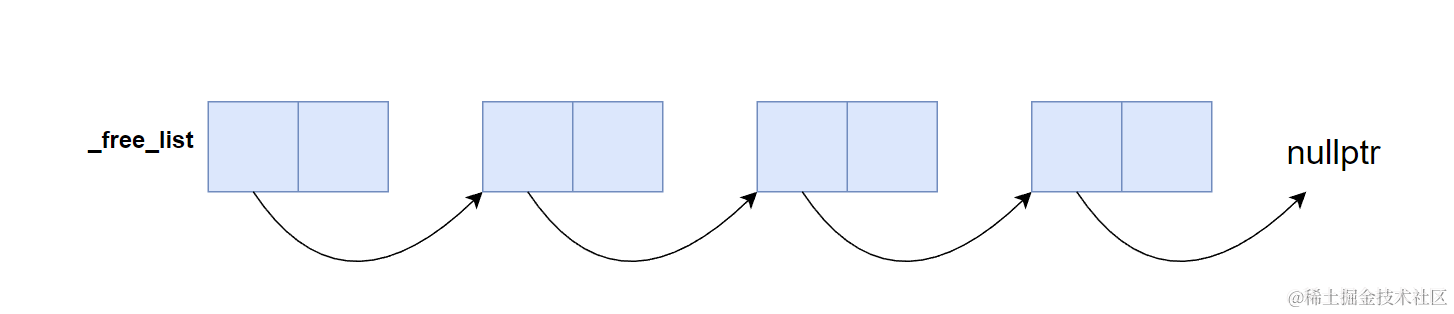
解放済みメモリの管理
返却されたメモリブロックは自由リストで管理します。自由リストは利用可能なメモリブロックのリストであり、各ノードは利用可能なブロックを表します。割り当て時には自由リストからブロックを取得し、解放時にはそのブロックを自由リストに追加します。
特別なリンクリスト構造を設計する必要はなく、メモリブロックの先頭4バイト(32bit)または8バイト(64bit)に次のブロックのアドレスを格納します。解放時は自由リストへの先頭挿入(頭挿入)を行います。

注意:32bitプラットフォームでは、要求オブジェクトが4バイト未満の場合でも、自由リスト用に最低4バイト確保するようにします。
固定長メモリプールの実装
template<class T>
class ObjectPool
{
public:
T* New()
{
T* obj = nullptr;
// 先に解放済みメモリブロックを使用
if (_free_list != nullptr)
{
void* next = *((void**)_free_list);
obj = (T*)_free_list;
_free_list = next;
}
else
{
// 残りが足りない場合、新しい領域を確保
if (_remain_bytes < sizeof(T))
{
_remain_bytes = 128 * 1024;
_memory = (char*)malloc(_remain_bytes);
if (_memory == nullptr)
{
printf("malloc fail");
exit(-1);
}
}
obj = (T*)_memory;
size_t obj_size = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
_memory += obj_size;
_remain_bytes -= obj_size;
}
// 配置newでオブジェクトを構築
new(obj)T;
return obj;
}
void Delete(T* obj)
{
// 明示的にデストラクタを呼ぶ
obj->~T();
// 自由リストに頭挿入
*(void**)obj = _free_list;
_free_list = obj;
}
private:
char* _memory = nullptr;
size_t _remain_bytes = 0;
void* _free_list = nullptr;
};
解説:
- 割り当て処理
まず128KBを確保し、オブジェクト obj にその先頭アドレスを設定。

オブジェクトサイズがポインタサイズ未満ならポインタサイズまで拡張。例えば32バイトの場合、_memory を32バイト進め、残りを減らす。

最後に配置newでオブジェクトを構築し、ポインタを返す。
- 解放処理:
解放されたメモリブロックを自由リストに頭挿入する。ブロックの先頭4(または8)バイトに次のブロックアドレスを格納する。これには void** へのキャストとデリファレンスを用いる。void** のデリファレンスは32bitでは4バイト、64bitでは8バイトのアクセスになるため、プラットフォームに依存しない方法となる。
自由リストへの頭挿入(32bitの例):
最初の挿入では _free_list == nullptr の状態。ブロックの先頭4バイトに _free_list(nullptr)を設定し、_free_list をそのブロックに向ける。

2回目以降も同様に、新しいブロックの先頭に現在の _free_list を設定し、_free_list を新しいブロックに更新する。
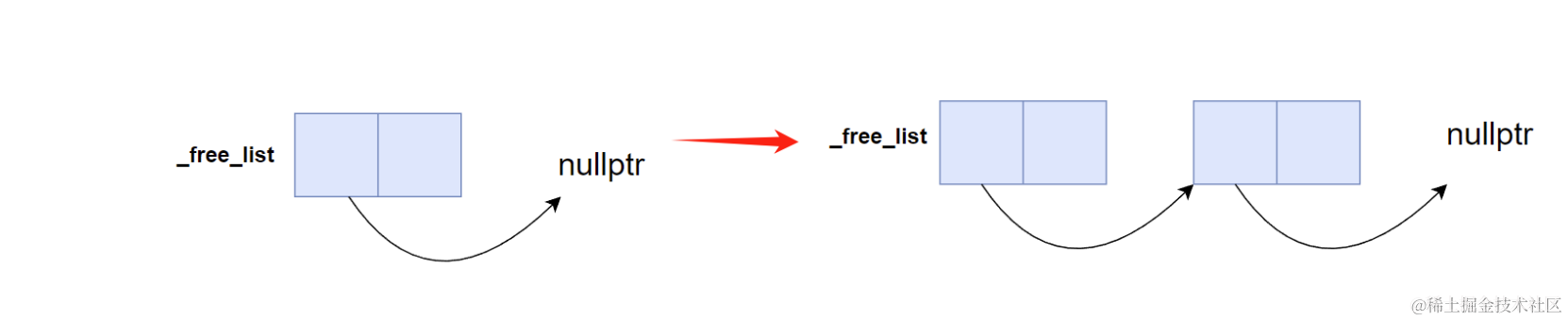
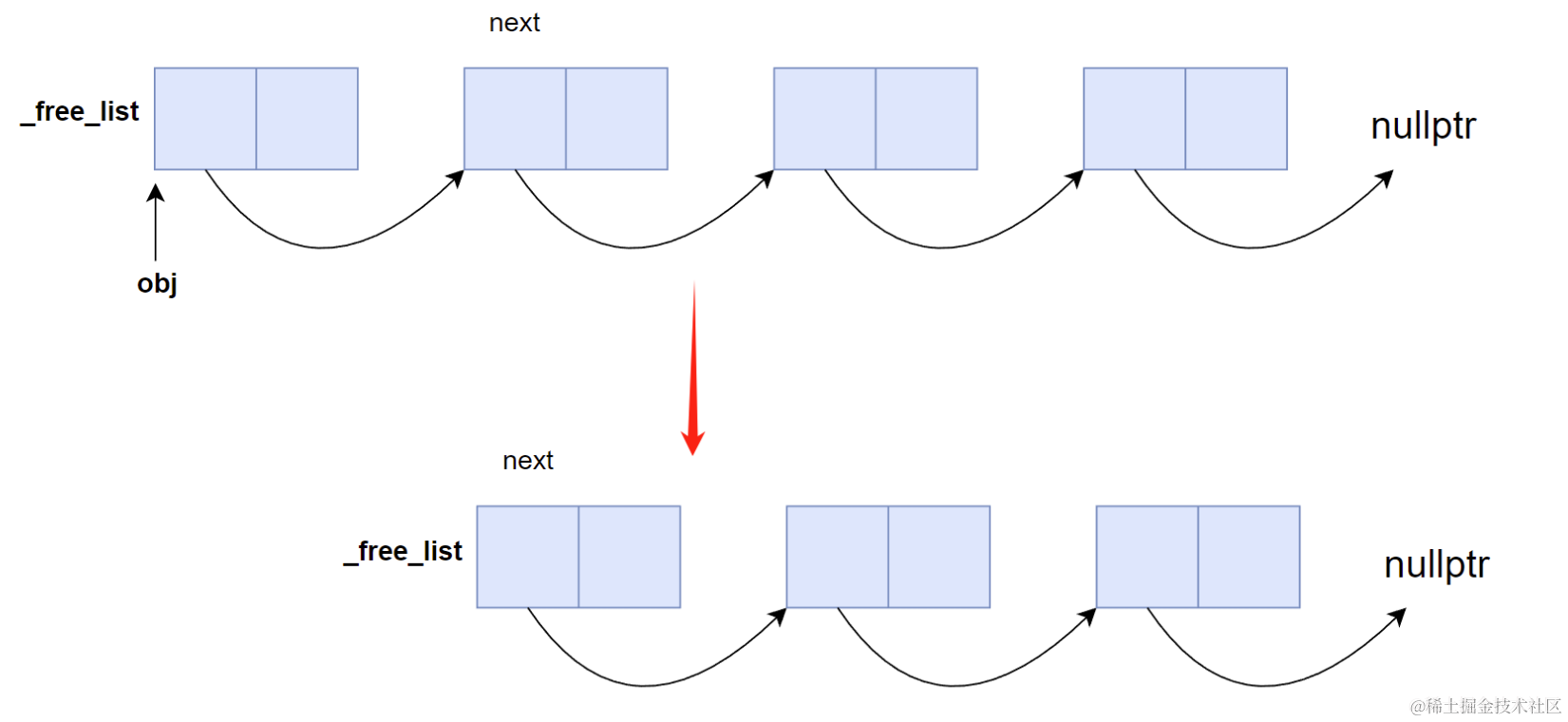
これで、毎回同じロジックで頭挿入できる。
次回割り当て時は、自由リストが空でなければそちらから取得する。
void* next = *((void**)_free_list);
obj = (T*)_free_list;
_free_list = next;
パフォーマンス比較
パフォーマンステストは Release モードで行う。
-
組み込み型での比較:
void test() { const size_t Rounds = 5; const size_t N = 10000000; std::vector<int*> v1; v1.reserve(N); size_t begin1 = clock(); for (int i = 0; i < Rounds; ++i) { for (int j = 0; j < N; ++j) v1.push_back(new int()); for (int j = 0; j < N; ++j) delete v1[j]; v1.clear(); } size_t end1 = clock(); std::vector<int*> v2; v2.reserve(N); ObjectPool<int> obj_pool; size_t begin2 = clock(); for (int i = 0; i < Rounds; ++i) { for (int j = 0; j < N; ++j) v2.push_back(obj_pool.New()); for (int j = 0; j < N; ++j) obj_pool.Delete(v2[j]); v2.clear(); } size_t end2 = clock(); cout << "USE NEW TIME = :" << end1 - begin1 << endl; cout << "USE OBJECTPOOL TIME = :" << end2 - begin2 << endl; }実行結果:
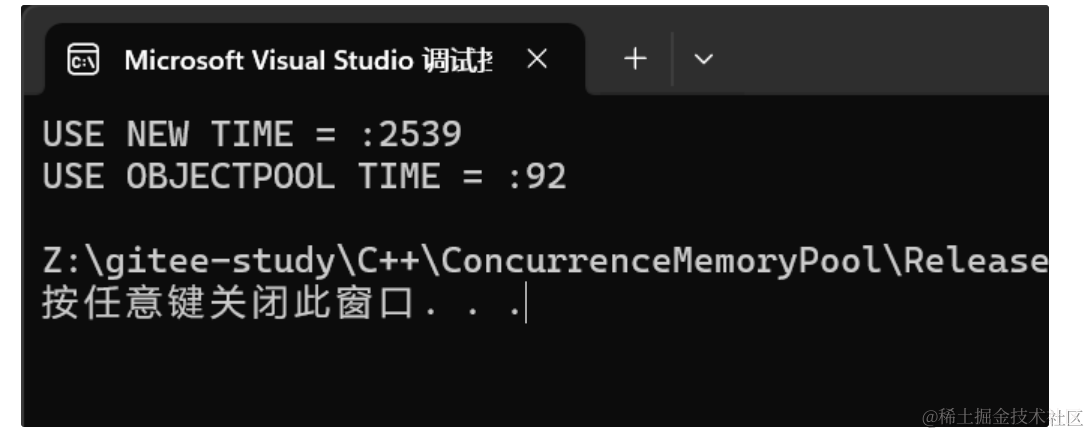
1000万回の割り当て・解放を5ラウンド行った場合、メモリプールは約27倍高速。
-
カスタム型
二分木ノードクラスを定義:
struct TreeNode { int _val; TreeNode* _left; TreeNode* _right; TreeNode() : _val(0), _left(nullptr), _right(nullptr) {} };テスト:
void test() { const size_t Rounds = 5; const size_t N = 10000000; std::vector<TreeNode*> v1; v1.reserve(N); size_t begin1 = clock(); for (int i = 0; i < Rounds; ++i) { for (int j = 0; j < N; ++j) v1.push_back(new TreeNode()); for (int j = 0; j < N; ++j) delete v1[j]; v1.clear(); } size_t end1 = clock(); std::vector<TreeNode*> v2; v2.reserve(N); ObjectPool<TreeNode> obj_pool; size_t begin2 = clock(); for (int i = 0; i < Rounds; ++i) { for (int j = 0; j < N; ++j) v2.push_back(obj_pool.New()); for (int j = 0; j < N; ++j) obj_pool.Delete(v2[j]); v2.clear(); } size_t end2 = clock(); cout << "USE NEW TIME = :" << end1 - begin1 << endl; cout << "USE OBJECTPOOL TIME = :" << end2 - begin2 << endl; }実行結果:
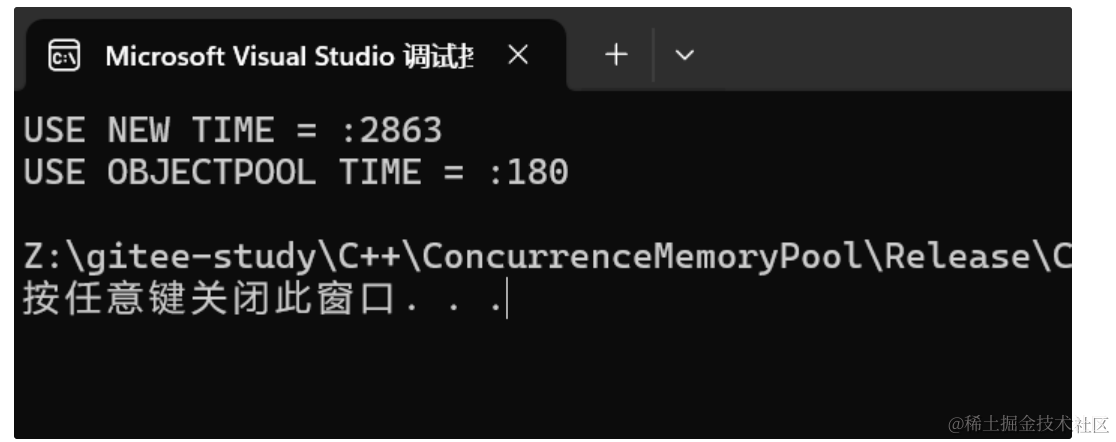
約18倍高速。
メモリプールと
newは内部的にmallocを利用している
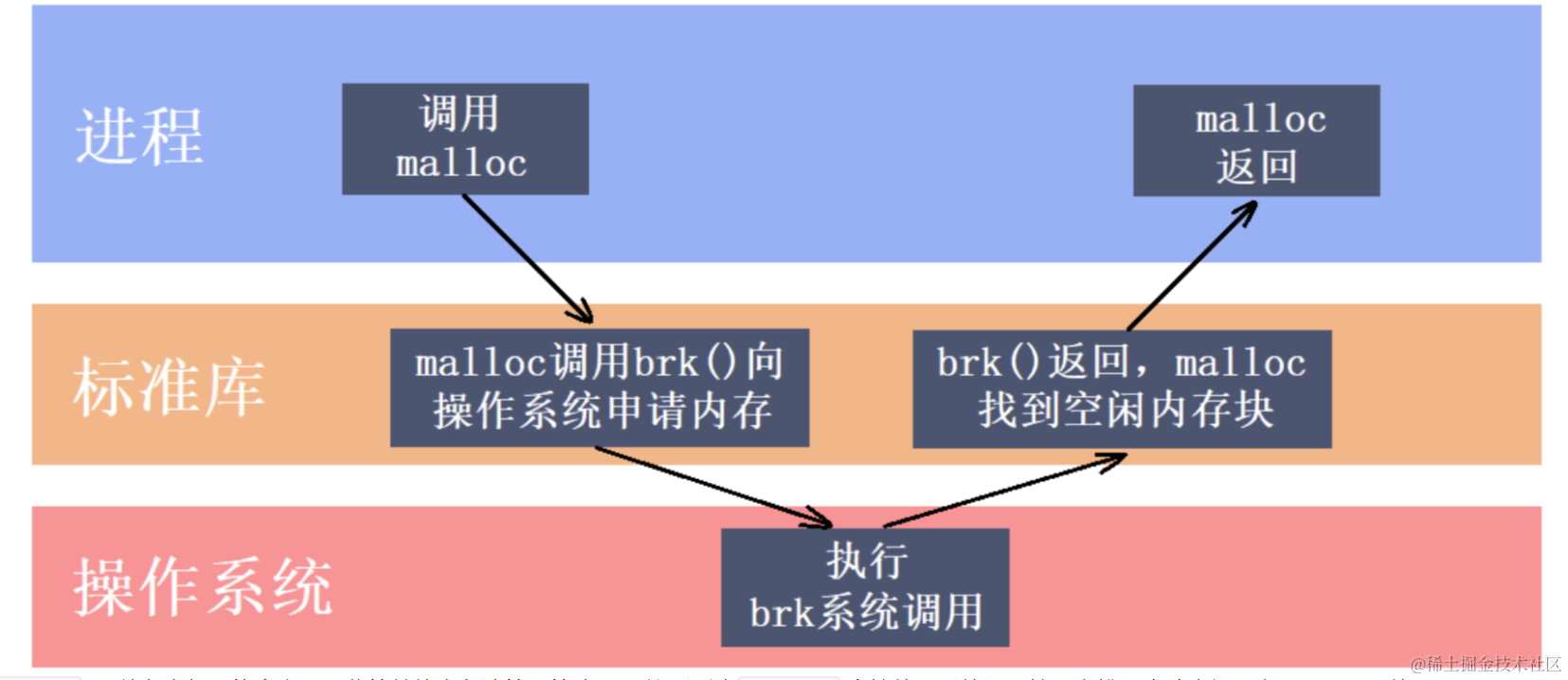
malloc 自体もメモリプール戦略を持つことがある。OSのシステムコールを直接使うこともできる。Windowsでは VirtualAlloc、Linuxでは brk や mmap を使用する。
#ifdef _WIN32
#include <Windows.h>
#else
// Linux
#endif
inline static void* SystemAlloc(size_t kpage)
{
#ifdef _WIN32
void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#else
void* ptr = mmap(0, kpage << 13, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS, -1, 0);
#endif
if (ptr == nullptr) { printf("malloc fail"); exit(-1); }
return ptr;
}
メモリプールの New で SystemAlloc を利用すれば、malloc から完全に独立できる。
VirtualAlloc はページ単位(通常8KB)でメモリを割り当てる。
2. 高并发メモリプール (Concurrent Memory Pool)
高并发マルチスレッド環境では、メモリ割り当て時に激しいロック競争が発生する。malloc 自体は優秀だが、并发シナリオでは頻繁なロック取得/解放により効率が低下する。本プロジェクトの原型 tcmalloc は、マルチスレッド・高并发シナリオで優れたメモリプールを実現する。
固定長メモリプールと異なり、高并发メモリプールはメモリフラグメント問題と効率問題に加え、マルチスレッド環境でのロック競争も解決する必要がある。
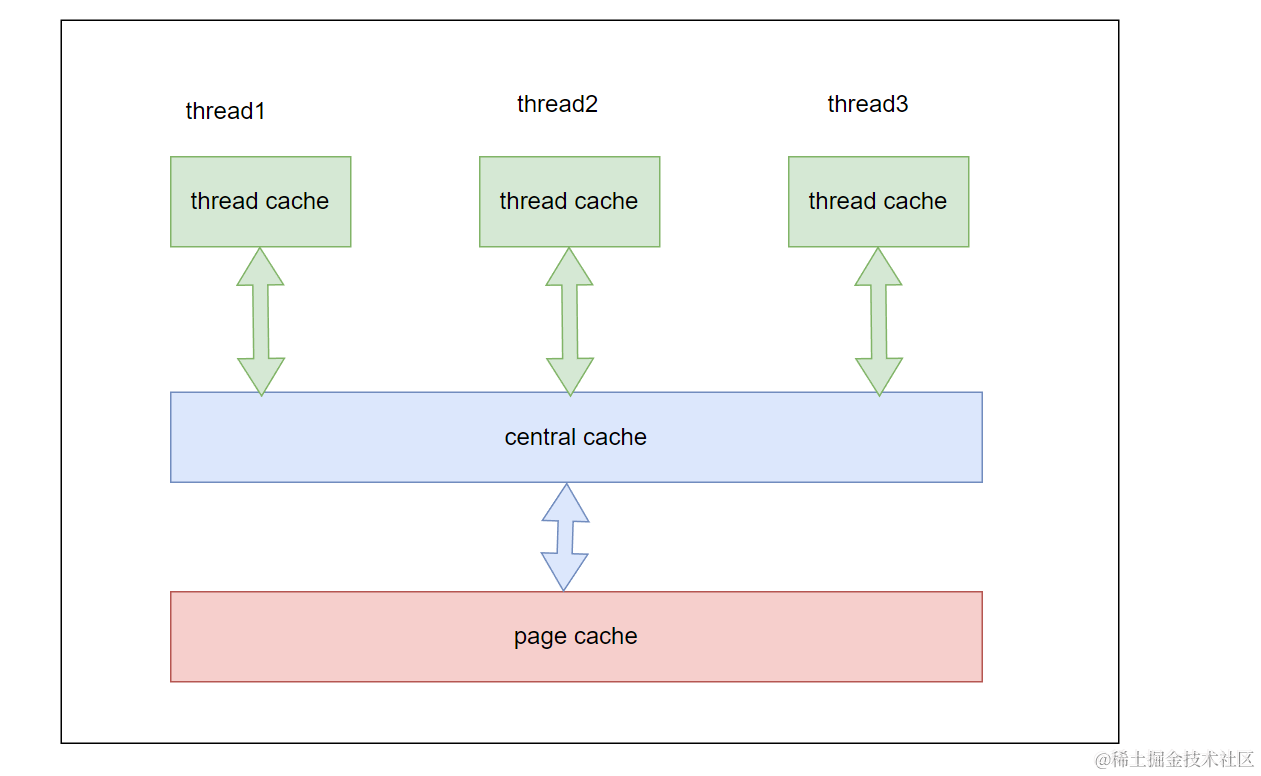
Concurrent Memory Pool は主に3つの部分から構成される:
-
スレッドキャッシュ (thread cache):
各スレッドが専用のローカルメモリキャッシュを持ち、ロック競争を低減する。256KB未満のメモリ割り当てに使用され、ロック不要で高速。 -
中央キャッシュ (central cache):
全スレッドで共有され、thread cache が必要に応じてオブジェクトを取得する。周期的に thread cache からオブジェクトを回収し、メモリの偏りを防ぐ。競合が発生するためロック保護が必要。 -
ページキャッシュ (page cache):
central cache の上位層で、メモリをページ単位で管理・割り当てる。central cache にメモリがない場合、page cache からページを取得し、固定サイズの小さなブロックに分割して渡す。不足時はヒープから確保する。
2.1 Thread Cache
高并发メモリプールでは異なるサイズのメモリ割り当てをサポートするため、複数の自由リスト(ハッシュバケット)が必要。Thread Cache は本質的にハッシュバケットであり、各バケットは異なるサイズの自由リストを持つ。
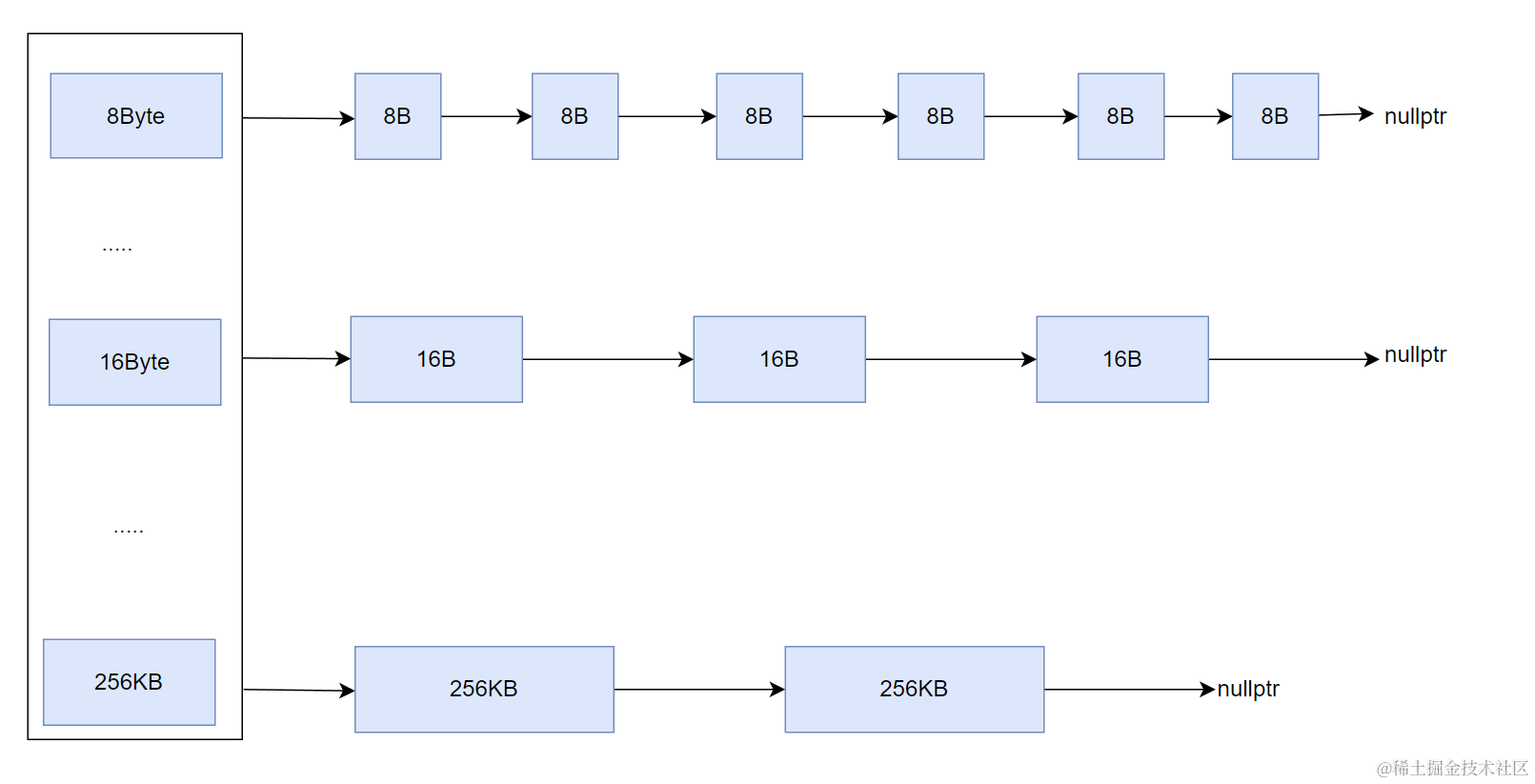
Thread Cache は 256KB 未満の割り当てをサポート。最小8バイト(64bit環境で自由リスト管理のため)。
8バイトから256KBまでのすべてのサイズに個別の自由リストを用意すると 26万個以上のバケットが必要になり非現実的。そこで tcmalloc に倣い、アライメント規則を導入する。
アライメント規則:
| バイト数 | アライメント | 自由リストインデックス |
|---|---|---|
| [1-128] | 8 Byte | [0,16) |
| [128+1,1024] | 16 Byte | [16,72) |
| [1024+1, 8*1024] | 128 Byte | [72,128) |
| [8*1024+1, 64*1024] | 1024 Byte | [128,184) |
| [64*1024+1, 256*1024] | 8*1024 Byte | [184,208) |
これによりバケット数は208個(インデックス0~207)に抑えられる。
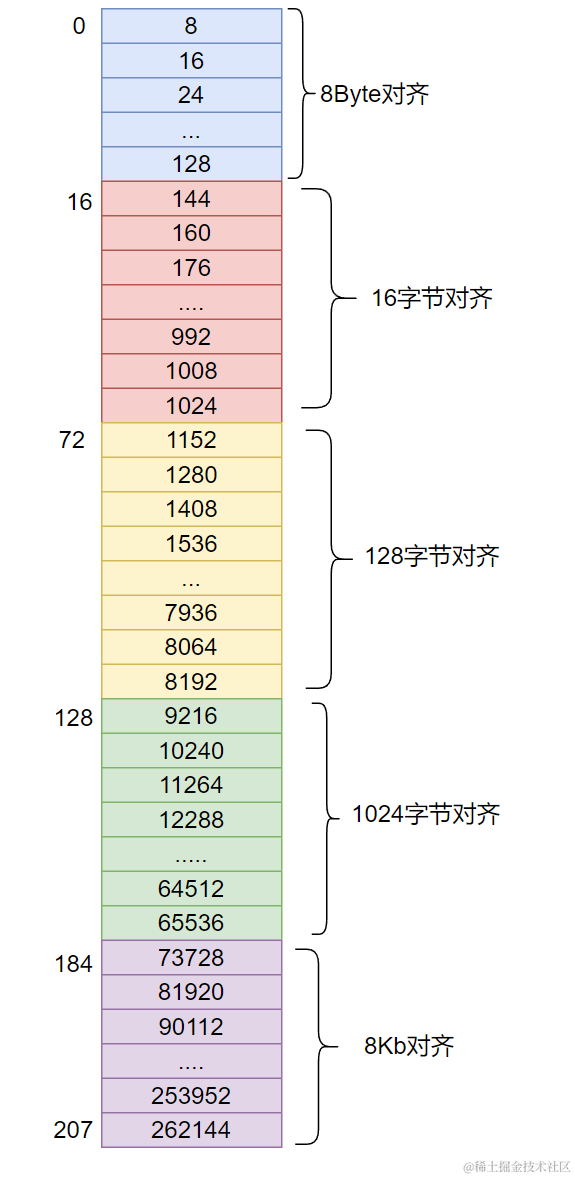
空間浪費率は約10%に抑えられる。
class SizeClass
{
public:
static const size_t MAX_BYTES = 256 * 1024;
static inline size_t _RoundUp(size_t bytes, size_t align)
{
return ((bytes + align - 1) & ~(align - 1));
}
static inline size_t RoundUp(size_t bytes)
{
assert(bytes <= MAX_BYTES);
if (bytes <= 128) return _RoundUp(bytes, 8);
else if (bytes <= 1024) return _RoundUp(bytes, 16);
else if (bytes <= 8 * 1024) return _RoundUp(bytes, 128);
else if (bytes <= 64 * 1024) return _RoundUp(bytes, 1024);
else if (bytes <= 256 * 1024) return _RoundUp(bytes, 8 * 1024);
else { assert(false); return -1; }
}
};
2.1.1 Thread Cache の実装
自由リストをカプセル化:
class FreeList
{
public:
void Push(void* obj)
{
*(void**)obj = _free_list;
_free_list = obj;
++_size;
}
void PushRound(void* start, void* end, size_t size)
{
*(void**)end = _free_list;
_free_list = start;
_size += size;
}
void* Pop()
{
void* next = *((void**)_free_list);
void* obj = _free_list;
_free_list = next;
--_size;
return obj;
}
void PopRound(void*& start, void*& end, size_t size)
{
start = _free_list;
end = start;
for (size_t i = 0; i < size - 1; ++i)
end = NextObj(end);
_free_list = NextObj(end);
_size -= size;
NextObj(end) = nullptr;
}
bool IsEmpty() { return _free_list == nullptr; }
size_t& MaxSize() { return _max_size; }
size_t Size() { return _size; }
private:
void* _free_list = nullptr;
size_t _max_size = 1;
size_t _size = 0;
};
ThreadCache クラス:
#pragma once
#include "Common.h"
class ThreadCache
{
public:
void* Allocate(size_t size);
void Deallocate(void* ptr, size_t size);
void* FetchFromCentralCache(size_t index, size_t size);
void ListTooLong(FreeList& list, size_t size);
private:
FreeList _free_list[NFREELISTS]; // 208個のバケット
};
static __declspec(thread) ThreadCache* tls_threadcache = nullptr;
2.1.2 ロック不要の并发アクセス
各スレッドが独立した ThreadCache オブジェクトを持つため、小さいオブジェクトの割り当てにロックが不要。これを実現するためにスレッドローカルストレージ(TLS)を使用。
static __declspec(thread) ThreadCache* tls_threadcache = nullptr;
初期化:
static ObjectPool<ThreadCache> thread_cache_pool;
tls_threadcache = thread_cache_pool.New();
2.1.3 Thread Cache からのメモリ割り当て
void* ThreadCache::Allocate(size_t size)
{
assert(size <= MAX_BYTES);
size_t index = SizeClass::Index(size);
size_t align_size = SizeClass::RoundUp(size);
if (_free_list[index].IsEmpty())
{
return FetchFromCentralCache(index, align_size);
}
else
{
return _free_list[index].Pop();
}
}
中央キャッシュからの取得はバッチ処理で行い、効率を向上。スロースタートアルゴリズムを採用。
static size_t NumMoveSize(size_t size)
{
assert(size > 0);
int num = MAX_BYTES / size;
if (num < 2) num = 2;
if (num > 512) num = 512;
return num;
}
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{
size_t batch_num = min(_free_list[index].MaxSize(), SizeClass::NumMoveSize(size));
if (batch_num == _free_list[index].MaxSize())
_free_list[index].MaxSize() += 1;
void* start = nullptr;
void* end = nullptr;
size_t actual_num = CentralCache::GetInstace()->FetchRangeObj(start, end, batch_num, size);
assert(actual_num >= 1);
if (actual_num == 1)
return start;
else
{
_free_list[index].PushRound(NextObj(start), end, actual_num - 1);
return start;
}
}
2.1.4 Thread Cache からのメモリ解放
void ThreadCache::Deallocate(void* ptr, size_t size)
{
size_t index = SizeClass::Index(size);
_free_list[index].Push(ptr);
if (_free_list[index].Size() >= _free_list[index].MaxSize())
{
ListTooLong(_free_list[index], size);
}
}
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
list.PopRound(start, end, list.MaxSize());
CentralCache::GetInstace()->ReleaseListToSpans(start, size);
}
2.2 Central Cache
2.2.1 設計フレームワーク
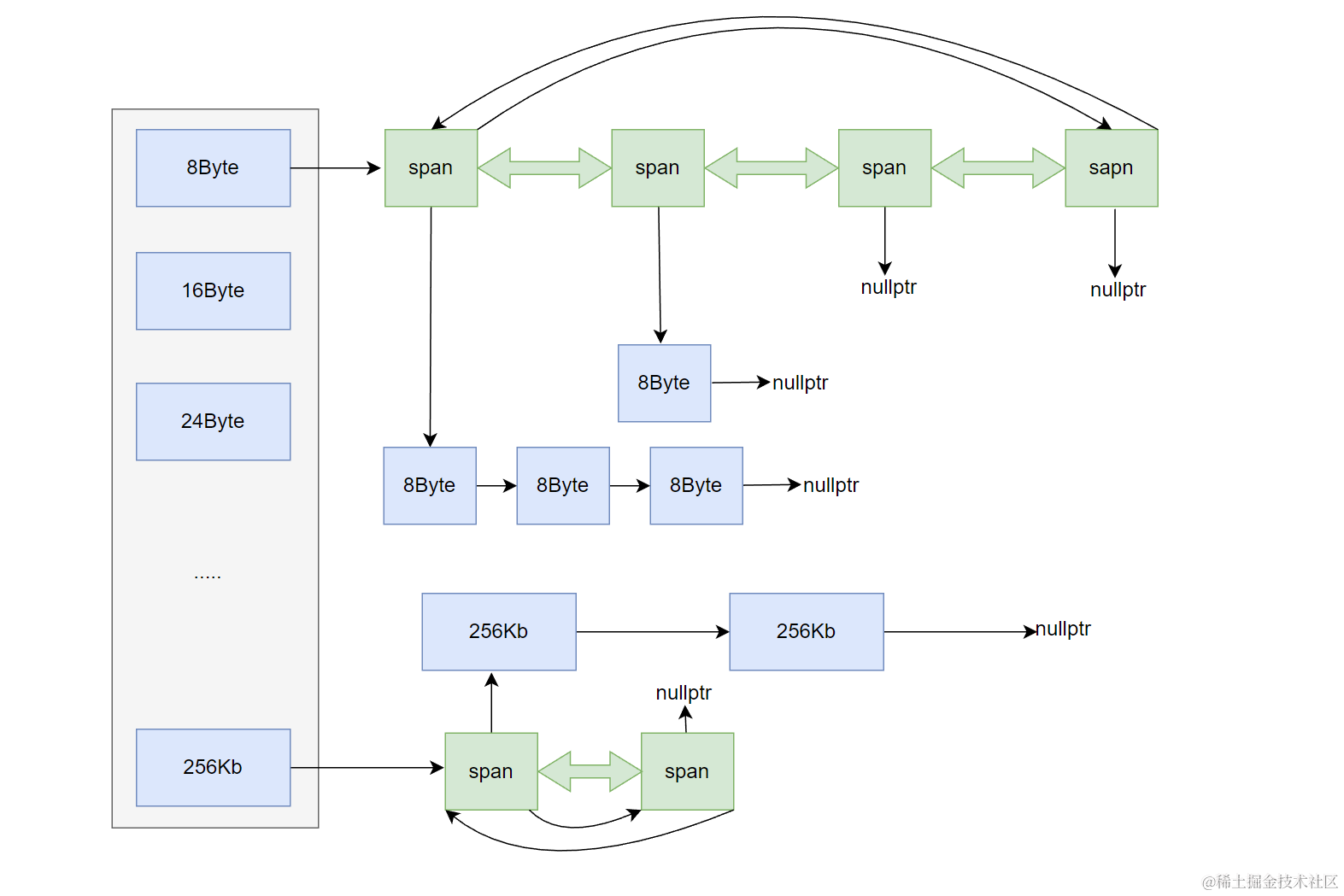
Central Cache は Thread Cache と同様のハッシュバケット構造を持つが、全体で1つのインスタンス(シングルトン)であり、スレッド間で共有される。ロックはバケット単位(桶ロック)で行い、異なるバケットへのアクセスは並行可能。
Central Cache の各バケットは Span オブジェクトを保持する。Span はページ単位の大きなメモリブロックを管理し、双方向循環リストで連結される。各 Span は自身の自由リストを持ち、小さなブロックに分割されている。
2.2.2 Span
struct Span
{
PAGE_ID _page_id = 0;
size_t _page_num = 0;
Span* _prev = nullptr;
Span* _next = nullptr;
size_t _obj_size = 0;
size_t _use_count = 0;
void* _free_list = nullptr;
bool _is_use = false;
};
Span の双方向循環リスト:
class SpanList
{
public:
SpanList()
{
_head = new Span;
_head->_next = _head;
_head->_prev = _head;
}
Span* Begin() { return _head->_next; }
Span* End() { return _head; }
void Insert(Span* cur, Span* newspan) { /* ... */ }
void Erase(Span* cur) { /* ... */ }
bool Empty() { return _head->_next == _head; }
void PushFront(Span* newspan) { Insert(Begin(), newspan); }
Span* PopFront() { Span* front = _head->_next; Erase(front); return front; }
private:
Span* _head = nullptr;
public:
std::mutex _bucket_lock;
};
2.2.3 Central Cache の実装(シングルトン)
class CentralCache
{
public:
static CentralCache* GetInstace() { return &_inst; }
CentralCache(const CentralCache&) = delete;
CentralCache& operator=(const CentralCache) = delete;
size_t FetchRangeObj(void*& start, void*& end, size_t num, size_t size);
Span* GetOneSpan(SpanList& list, size_t byte_size);
void ReleaseListToSpans(void* start, size_t byte_size);
private:
CentralCache() {}
SpanList _span_lists[NFREELISTS];
static CentralCache _inst;
};
2.2.4 FetchRangeObj
size_t CentralCache::FetchRangeObj(void*& start, void*& end, size_t batch_num, size_t size)
{
size_t index = SizeClass::Index(size);
_span_lists[index]._bucket_lock.lock();
Span* span = GetOneSpan(_span_lists[index], size);
assert(span != nullptr);
assert(span->_free_list != nullptr);
start = span->_free_list;
end = start;
size_t i = 0;
size_t actual_num = 1;
while (NextObj(end) != nullptr && (i < batch_num - 1))
{
end = NextObj(end);
actual_num++;
++i;
}
span->_free_list = NextObj(end);
NextObj(end) = nullptr;
span->_use_count += actual_num;
_span_lists[index]._bucket_lock.unlock();
return actual_num;
}
2.2.5 GetOneSpan
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{
// まず既存のspanを検索
Span* iter = list.Begin();
while (iter != list.End())
{
if (iter->_free_list != nullptr) return iter;
else iter = iter->_next;
}
// 存在しなければPage Cacheから取得
list._bucket_lock.unlock(); // ロックを一時解放
PageCache::GetInstance()->_page_mtx.lock();
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
span->_is_use = true;
span->_obj_size = size;
PageCache::GetInstance()->_page_mtx.unlock();
// spanの大きなメモリブロックを固定サイズに分割
char* start = (char*)(span->_page_id << PAGE_SHIFT);
size_t byte_size = span->_page_num << PAGE_SHIFT;
char* end = start + byte_size;
span->_free_list = start;
start += size;
void* tail = span->_free_list;
while (start < end)
{
NextObj(tail) = start;
tail = start;
start += size;
}
NextObj(tail) = nullptr;
list._bucket_lock.lock(); // ロックを再取得
list.PushFront(span);
return span;
}
2.2.6 ReleaseListToSpans
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
size_t index = SizeClass::Index(size);
_span_lists[index]._bucket_lock.lock();
while (start != nullptr)
{
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
void* next = NextObj(start);
*(void**)start = span->_free_list;
span->_free_list = start;
span->_use_count--;
if (span->_use_count == 0)
{
_span_lists[index].Erase(span);
span->_free_list = nullptr;
span->_next = span->_prev = nullptr;
_span_lists[index]._bucket_lock.unlock();
PageCache::GetInstance()->_page_mtx.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_page_mtx.unlock();
_span_lists[index]._bucket_lock.lock();
}
start = next;
}
_span_lists[index]._bucket_lock.unlock();
}
2.3 Page Cache
2.3.1 設計フレームワーク
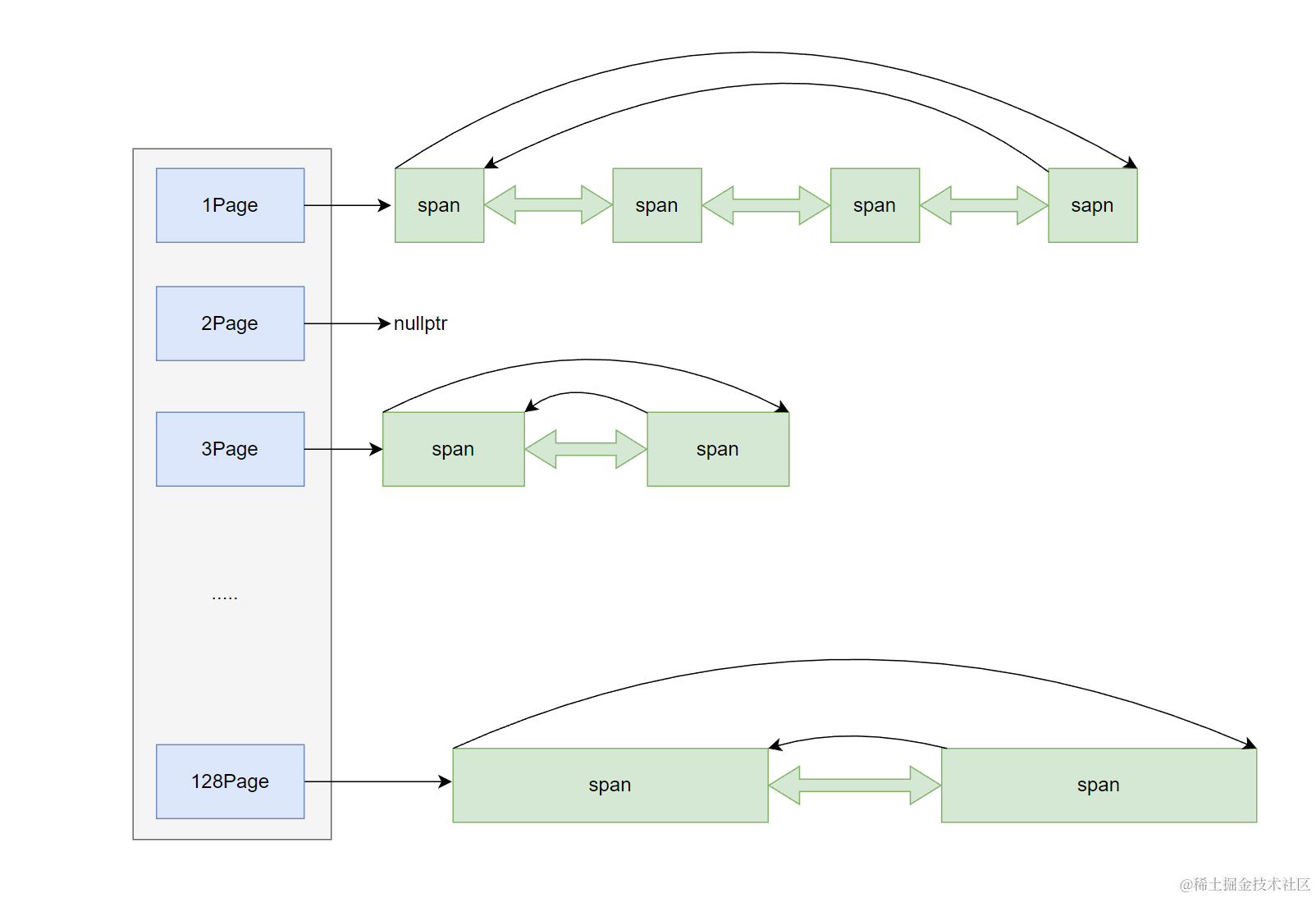
Page Cache はハッシュバケット構造で、各バケットは Span の双方向循環リスト。ページ数に基づいてマッピング(1ページ→バケット1、2ページ→バケット2、…、128ページ→バケット128)。最大128ページまで管理。
2.3.2 Page Cache の実装(シングルトン)
class PageCache
{
public:
static PageCache* GetInstance() { return &_inst; }
PageCache(const PageCache&) = delete;
PageCache& operator=(const PageCache) = delete;
Span* NewSpan(size_t size);
Span* MapObjectToSpan(void* obj);
void ReleaseSpanToPageCache(Span* span);
std::mutex _page_mtx;
private:
PageCache() {}
static PageCache _inst;
SpanList _span_list[PAGE_NUMS];
// マッピング用(基数木で最適化後)
TCMalloc_PageMap1<32 - PAGE_SHIFT> _id_span_map;
ObjectPool<Span> _span_pool;
};
2.3.3 NewSpan
Span* PageCache::NewSpan(size_t size)
{
if (size > PAGE_NUMS - 1) // 128ページ超
{
void* ptr = SystemAlloc(size);
Span* span = _span_pool.New();
span->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_page_num = size;
_id_span_map.set(span->_page_id, span);
_id_span_map.set(span->_page_id + span->_page_num - 1, span);
return span;
}
if (!_span_list[size].Empty())
{
Span* kspan = _span_list[size].PopFront();
for (PAGE_ID i = 0; i < kspan->_page_num; ++i)
_id_span_map.set(kspan->_page_id + i, kspan);
return kspan;
}
for (int i = size + 1; i < PAGE_NUMS; ++i)
{
if (!_span_list[i].Empty())
{
Span* nspan = _span_list[i].PopFront();
Span* kspan = _span_pool.New();
kspan->_page_id = nspan->_page_id;
kspan->_page_num = size;
nspan->_page_id += size;
nspan->_page_num -= size;
_span_list[nspan->_page_num].PushFront(nspan);
_id_span_map.set(nspan->_page_id, nspan);
_id_span_map.set(nspan->_page_id + nspan->_page_num - 1, nspan);
for (PAGE_ID i = 0; i < kspan->_page_num; ++i)
_id_span_map.set(kspan->_page_id + i, kspan);
return kspan;
}
}
// どのバケットにもない場合、ヒープから128ページ確保
Span* span = _span_pool.New();
void* ptr = SystemAlloc(PAGE_NUMS - 1);
span->_page_id = (PAGE_ID)ptr >> PAGE_SHIFT;
span->_page_num = PAGE_NUMS - 1;
_span_list[span->_page_num].PushFront(span);
return NewSpan(size); // 再帰的に分割
}
2.3.4 MapObjectToSpan
Span* PageCache::MapObjectToSpan(void* obj)
{
std::unique_lock<std::mutex> lock(_page_mtx);
PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);
return (Span*)_id_span_map.get(id);
}
2.3.5 ReleaseSpanToPageCache
void PageCache::ReleaseSpanToPageCache(Span* span)
{
size_t size = span->_page_num;
if (size > PAGE_NUMS - 1)
{
void* ptr = (void*)(span->_page_id << PAGE_SHIFT);
SystemFree(ptr);
_span_pool.Delete(span);
return;
}
// 前方結合
while (1)
{
PAGE_ID prev_page = span->_page_id - 1;
auto ret = _id_span_map.get(prev_page);
if (ret == nullptr) break;
Span* prev_span = (Span*)ret;
if (prev_span->_is_use) break;
if (prev_span->_page_num + span->_page_num > PAGE_NUMS - 1) break;
span->_page_num += prev_span->_page_num;
span->_page_id = prev_span->_page_id;
_span_list[prev_span->_page_num].Erase(prev_span);
_span_pool.Delete(prev_span);
}
// 後方結合
while (1)
{
PAGE_ID next_page = span->_page_id + span->_page_num;
auto ret = _id_span_map.get(next_page);
if (ret == nullptr) break;
Span* next_span = (Span*)ret;
if (next_span->_is_use) break;
if (span->_page_num + next_span->_page_num > PAGE_NUMS - 1) break;
span->_page_num += next_span->_page_num;
_span_list[next_span->_page_num].Erase(next_span);
_span_pool.Delete(next_span);
}
_span_list[span->_page_num].PushFront(span);
span->_is_use = false;
_id_span_map.set(span->_page_id, span);
_id_span_map.set(span->_page_id + span->_page_num - 1, span);
}
3. パフォーマンステスト
メモリプールと malloc を比較。同じスレッド数・ラウンドで同時実行。
#include "ConcurrentAlloc.h"
#include <atomic>
void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
std::vector<std::thread> vthread(nworks);
std::atomic<size_t> malloc_costtime = 0, free_costtime = 0;
for (size_t k = 0; k < nworks; ++k)
{
vthread[k] = std::thread([&, k]() {
std::vector<void*> v; v.reserve(ntimes);
for (size_t j = 0; j < rounds; ++j)
{
size_t b1 = clock();
for (size_t i = 0; i < ntimes; i++) v.push_back(malloc(16));
size_t e1 = clock();
size_t b2 = clock();
for (size_t i = 0; i < ntimes; i++) free(v[i]);
size_t e2 = clock();
v.clear();
malloc_costtime += (e1 - b1);
free_costtime += (e2 - b2);
}
});
}
for (auto& t : vthread) t.join();
printf("...");
}
void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds)
{
// 同様に ConcurrentAlloc/ConcurrentFree を使用
}
パフォーマンス測定の結果、MapObjectToSpan での std::unordered_map によるロック競争がボトルネックであることが判明。そこで基数木(Radix Tree)を用いて最適化。
3.1 基数木による最適化
基数木は固定サイズの配列を持ち、拡張が発生しないためロックフリーでアクセス可能。32bit環境では2^19ページ(8KB/ページ)があり、各エントリ4バイトの配列で約2MBのメモリで十分。
template<int BITS>
class TCMalloc_PageMap1
{
public:
typedef uintptr_t Number;
explicit TCMalloc_PageMap1()
{
size_t size = sizeof(void*) << BITS;
_array = (void**)SystemAlloc(size >> PAGE_SHIFT);
memset(_array, 0, size);
}
void* get(Number k) const
{
if ((k >> BITS) > 0) return nullptr;
return _array[k];
}
void set(Number k, void* v)
{
assert(k >> BITS == 0);
_array[k] = v;
}
private:
void** _array;
static const int LENGTH = 1 << BITS;
};
使用例:
TCMalloc_PageMap1<32 - PAGE_SHIFT> _id_span_map;
基数木を使用した結果、unordered_map より9倍、malloc より3倍高速(DEBUG)。Releaseでは約2倍高速。
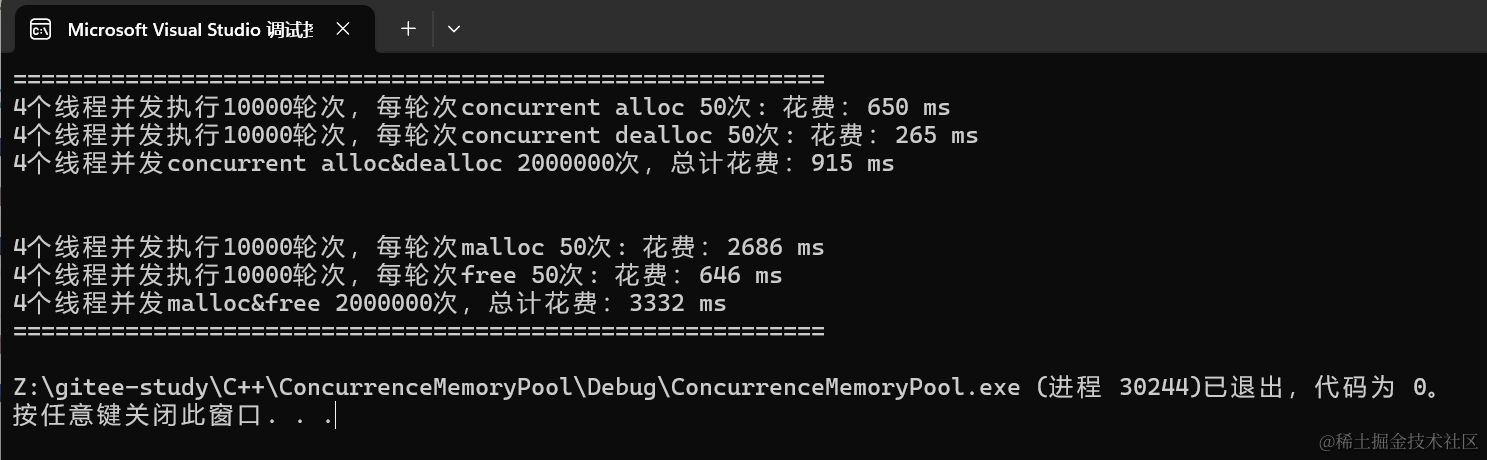
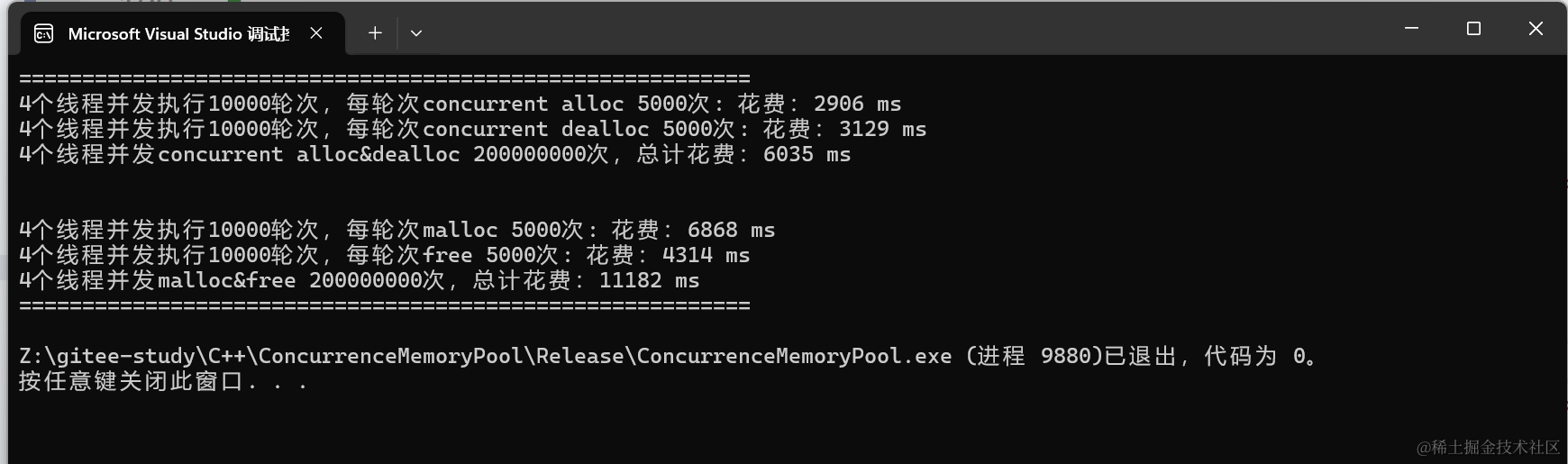
64bit環境では2^51ページになるため、多段基数木(2層、3層)を用いてメモリ使用量を抑える。